A data pipeline is a series of data processing steps where data is collected from various sources, cleaned, transformed consistently making it usable for various purposes such as business intelligence, analytics, machine learning, and reporting. The main goal of a data pipeline is to ensure that data flows smoothly from source to destination, keep data up to date, making it available in a useful format to end-users or downstream applications.
Data pipelines are critical in AI Factories. They provide the structured framework necessary for moving data through various stages—from ingestion and storage to processing and analysis—ensuring that data is available, reliable, and ready for use in AI model training and inference. Here’s how robust data pipelines empower AI factories:
- Scalability and Flexibility: AI models require vast amounts of data. Data pipelines designed for scalability handle this increasing volume without degradation in performance. Flexibility in these pipelines allows businesses to adapt quickly to new data sources and formats, which is crucial for AI models that must evolve with changing data landscapes.
- Speed and Efficiency: In an AI factory, speed is critical. Data pipelines automate the movement and transformation of data, reducing the time from data collection to insight generation. This efficiency is crucial for maintaining the rapid iteration cycles required in AI development.
- Quality and Accuracy: High-quality data is non-negotiable for effective AI solutions. Data pipelines enforce quality checks and validation at each step, ensuring the integrity and accuracy of the data feeding into AI models.
- Compliance and Security: As data travels through pipelines, ensuring its security and compliance with regulations (such as GDPR or HIPAA) is essential. Effective data pipelines embed security measures and compliance checks into their architecture, safeguarding data throughout its lifecycle.
What are the components of a typical data pipeline?
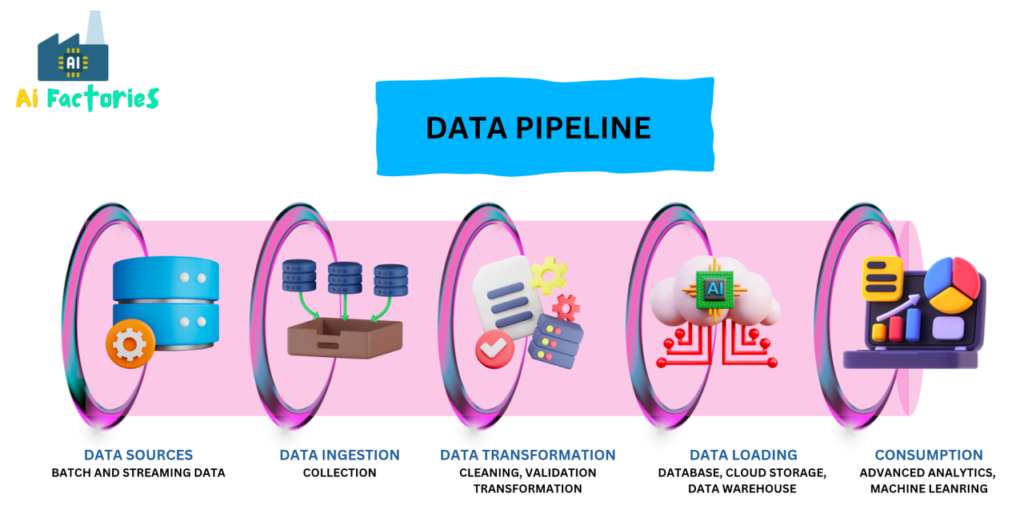
A typical data pipeline consists of several key components:
- Data Sources: This is where all your data comes from. It could be anything from databases and spreadsheets to social media and IoT devices.
- Data Ingestion: This step is about gathering data from various sources, which might include databases, APIs, or streaming platforms.
- Data Transformation: Here, the data is cleaned, validated, and transformed into a format or structure that’s ready for analysis or storage.
- Data Loading: After transformation, this data is loaded into a destination like a data warehouse, database, or cloud storage.
- Orchestration: This is the control center of the pipeline, managing the workflow and scheduling to ensure everything runs smoothly and efficiently.
What technologies are commonly used for building data pipelines?
Several technologies are commonly used to build data pipelines, each suited for different aspects of the process:
- Data Ingestion Tools: Technologies like Apache Kafka, Apache NiFi, and Amazon Kinesis help in the reliable collection and delivery of large volumes of data from various sources.
- Data Storage: Databases and data warehouses such as PostgreSQL, MongoDB, Amazon Redshift, Google BigQuery, and Snowflake are popular for storing structured and unstructured data.
- Data Processing and Transformation: Tools like Apache Spark, Apache Hadoop, and Apache Flink are used for processing large datasets and performing complex computations and transformations in real time or batch mode.
- ETL (Extract, Transform, Load) Tools: Software such as Talend, Informatica, and Microsoft SSIS are used for more traditional data manipulation tasks.
- Orchestration: Apache Airflow and Luigi are examples of workflow management tools used to coordinate the execution of different tasks in a data pipeline.
- Cloud Services: Many companies utilize cloud-based services like AWS Glue, Google Cloud Dataflow, and Azure Data Factory to build, automate, and manage data pipelines in the cloud.
These technologies can be combined in various ways to create efficient, scalable, and robust data pipelines tailored to specific business needs.
Building Efficient Data Pipelines for AI Factories
To construct a data pipeline that meets the demands of an AI factory, businesses need to focus on several key elements:
- Automated Data Ingestion: Use tools that support automated and continuous data ingestion modes to ensure that data feeds into the pipeline without manual intervention.
- Flexible Data Storage: Implement storage solutions that can handle structured, semi-structured, and unstructured data, providing the versatility needed for various AI applications.
- Advanced ETL Processes: Equip the pipeline with advanced ETL (Extract, Transform, Load) capabilities that can preprocess data efficiently, making it suitable for training sophisticated AI models.
- Real-Time Processing: Incorporate capabilities for real-time data processing to support AI applications that require immediate insights, such as dynamic pricing or fraud detection.
What are some best practices for designing and maintaining data pipelines?
Here are some best practices for designing and maintaining data pipelines:
- Set Clear Objectives: Begin by clearly defining the goals and requirements of your data pipeline, tailored to your organization’s specific needs.
- Ensure Data Quality: Implement robust data validation and error handling mechanisms to maintain the integrity of your data throughout the pipeline.
- Monitor Pipeline Performance: Keep track of metrics like data latency, throughput, and error rates. Set up alerting and logging systems to quickly identify and address issues.
- Secure the Data: Protect sensitive information during both transit and storage with appropriate security measures to prevent unauthorized access and data breaches.
- Use Version Control: Manage your pipeline code and configurations with version control systems. This enhances reproducibility, facilitates rollback, and aids in tracing changes over time.
- Regularly Optimize the Pipeline: Continuously review and refine your pipeline to adapt to new data sources, transformations, and scalability needs. Conduct load tests to ensure stability under peak loads and traffic spikes.
- Implement a Disaster Recovery Plan: Prepare for potential failures or outages with a comprehensive disaster recovery strategy to minimize downtime and data loss.
- Document Everything: Maintain detailed documentation of the pipeline’s architecture, dependencies, and data lineage. This is crucial for troubleshooting, future modifications, and onboarding new team members.
How can data pipelines be scaled for handling larger data volumes?
Scaling data pipelines to handle larger volumes of data effectively involves a combination of strategies:
- Use Distributed Computing: Technologies like Apache Spark and Hadoop allow for parallel processing of large datasets across many servers. This not only speeds up processing but also handles more data simultaneously.
- Leverage Cloud-Based Services: Cloud platforms offer auto-scaling capabilities which automatically adjust computing resources based on the workload. Services like AWS Glue, Azure Data Factory, and Google Cloud Dataflow can scale up or down as needed.
- Optimize Data Processing Algorithms: Review and refine your data processing algorithms and techniques to increase efficiency and minimize bottlenecks. Efficient use of resources can significantly speed up data processing times.
- Partition Data: Divide your data into smaller chunks that can be processed in parallel. This helps distribute the workload evenly across your infrastructure, making the processing faster and more efficient.
Implementing these strategies can help ensure that your data pipelines are robust enough to manage increased data volumes without compromising on performance.
How can data pipeline failures or errors be handled?
Handling failures and errors in data pipelines is crucial for maintaining data integrity and system reliability. Here are some effective strategies to manage such issues:
- Alerts and Notifications: Establish robust monitoring systems that can detect anomalies or failures in the pipeline. Set up automated alerts to notify the relevant team members immediately when something goes wrong.
- Retry Mechanisms: Incorporate retry logic into your pipeline so that if a task or stage fails, it automatically attempts to run again. This can often resolve temporary issues without the need for manual intervention.
- Detailed Logging: Maintain comprehensive logs that record detailed error information and system behavior. This data is invaluable for debugging and helps in identifying the root causes of failures.
- Data Validation and Quality Checks: Implement checks at various points in the pipeline to ensure data quality and consistency. This helps catch errors early, before they propagate through the system and cause more significant issues.
- Fault-Tolerant Design: Design your pipeline to be resilient to failures. This includes using distributed systems that can continue to operate even if part of the system fails, and implementing mechanisms to ensure data is not lost or corrupted.
By incorporating these strategies, you can enhance the resilience of your data pipelines, reducing downtime and ensuring data accuracy and availability.
Conclusion
The fusion of AI factories with robust data pipelines represents a strategic advantage in the digital age. As businesses continue to recognize the value of AI, investing in scalable, efficient, and secure data pipelines will not only enhance AI outputs but also drive significant business transformations. For companies looking to lead in innovation, building an AI factory supported by a strong data pipeline is not just an option—it’s an imperative for success.
For leaders embarking on this journey, the message is clear: prioritize your data pipeline to harness the full potential of your AI factory. The dividends, in terms of both efficiency and innovation, can redefine your competitive edge in the marketplace.
Other Episodes:
AI Factories: Episode 1 – So, what exactly is “AI Factories” or “AI Factory”?
AI Factories: Episode 2 – Virtuous Cycle in AI Factories
AI Factories: Episode 3 – The Components of AI Factories
👍 Like | 💬 Comment | 🔗 Share
#DataPipelines #DataOps #AI #ArtificialIntelligence #DataManagement #AgileData #DataFlow #DataIntegration #DataTransformation #BusinessIntelligence #DataScience #TechInnovation #DigitalTransformation #AIFactories #MachineLearning #DataScience #AITechnology #DigitalTransformation #AIInnovation #AIStrategy #AIManagement #AIEthics #AIGovernance #DataManagement #AIIndustryApplications #FutureOfAI