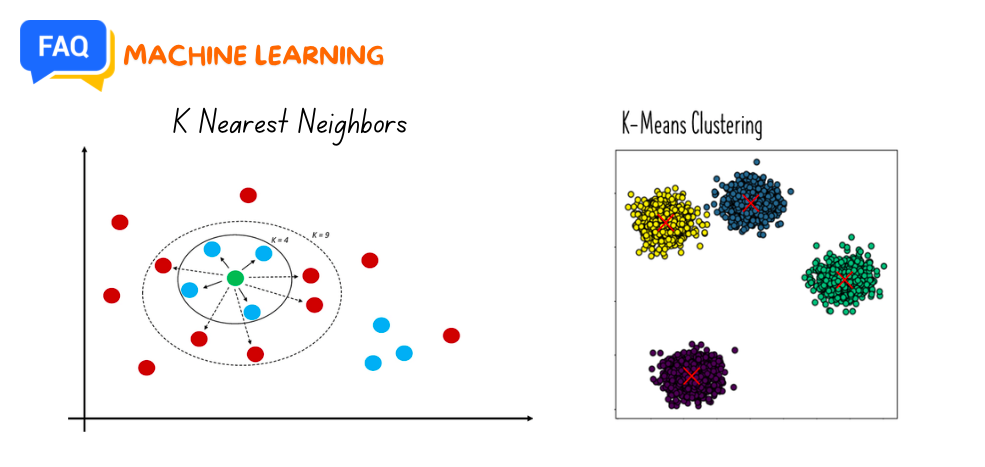
K Nearest Neighbours (KNN) and K-Means Clustering are both fundamental algorithms in machine learning, but they serve different purposes and operate in distinct ways. Here are the main differences between the two:
Purpose:
- K Nearest Neighbours (KNN):
- Type: Supervised learning algorithm.
- Use Case: Classification and regression tasks.
- Objective: Predict the class (or value) of a given data point based on the classes (or values) of its nearest neighbors.
- K-Means Clustering:
- Type: Unsupervised learning algorithm.
- Use Case: Clustering tasks.
- Objective: Partition a set of data points into 𝑘 clusters, where each data point belongs to the cluster with the nearest mean.
Mechanism:
- K Nearest Neighbours (KNN):
- Algorithm:
- Choose the number of neighbors 𝑘.
- Compute the distance between the query data point and all other points in the dataset.
- Select the 𝑘 nearest neighbors based on the computed distances.
- For classification, the predicted class is the majority class among the 𝑘 neighbors. For regression, the predicted value is the average of the 𝑘 neighbors’ values.
- Distance Metric: Commonly uses Euclidean distance, but other metrics like Manhattan or Minkowski distance can also be used.
- Training: Lazy learning algorithm, meaning it doesn’t build an explicit model during training. Instead, it stores the training data and performs computations during prediction.
- Algorithm:
- K-Means Clustering:
- Algorithm:
- Choose the number of clusters 𝑘.
- Initialize 𝑘 cluster centroids, often randomly.
- Assign each data point to the nearest centroid, forming 𝑘 clusters.
- Recalculate the centroids as the mean of all points in each cluster.
- Repeat steps 3 and 4 until convergence (i.e., the assignments no longer change or the centroids stabilize).
- Distance Metric: Typically uses Euclidean distance to determine the nearest centroid.
- Training: Iterative algorithm that builds a model by updating cluster centroids until a convergence criterion is met.
- Algorithm:
Data Dependency:
- K Nearest Neighbours (KNN):
- Dependency on Training Data: Heavily dependent, as it requires storing the entire training dataset for making predictions.
- Scalability: Less scalable with large datasets due to the need to compute distances for all points in the dataset for each prediction.
- K-Means Clustering:
- Dependency on Training Data: Less dependent once the model is trained, as the final centroids are used for new data points.
- Scalability: Generally more scalable, especially with optimizations like mini-batch K-means.
Output:
- K Nearest Neighbours (KNN):
- Output: Predicted class labels (for classification) or predicted values (for regression).
- K-Means Clustering:
- Output: Cluster assignments for each data point and the final positions of the centroids.
Example Scenarios:
- K Nearest Neighbours (KNN):
- Classification: Predicting whether an email is spam or not based on the similarity to previously labeled emails.
- Regression: Predicting the price of a house based on features like size, location, and historical prices of similar houses.
- K-Means Clustering:
- Clustering: Segmenting customers into distinct groups based on purchasing behavior for targeted marketing strategies.
- Image Compression: Reducing the number of colors in an image by clustering pixel values.
In summary, KNN is a supervised learning algorithm used for classification and regression, relying heavily on the training data to make predictions. K-Means is an unsupervised learning algorithm used for clustering, aiming to partition the data into 𝑘 distinct groups.